I did fast.ai lesson 2 which involved building your own classifier using images from the internet, and was interested in breaking down how exactly they downloaded images from a google image search (gonna assume it’ll be useful later).
They had you perform a search, then scroll enough to load a decent number of images, then run these two pretty lines of code in console:
urls = Array.from(document.querySelectorAll('.rg_di .rg_meta')).map(el=>JSON.parse(el.textContent).ou);
window.open('data:text/csv;charset=utf-8,' + escape(urls.join('\n')));
And out came a csv file of image urls! Let’s look at the main function used.
document.querySelectorAll
What’s important here is the css selectors chosen - .rg_di and .rg_meta.
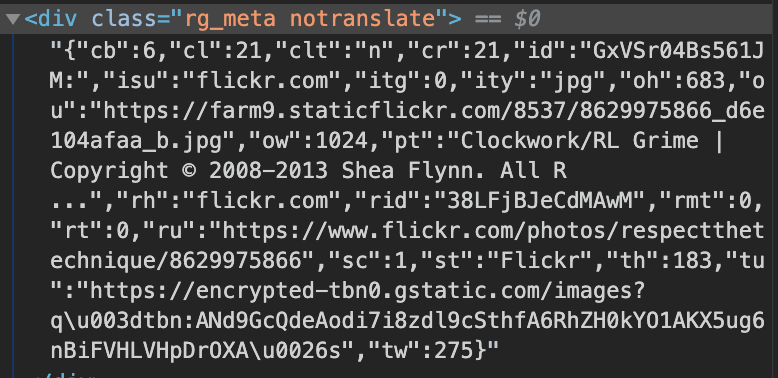
Looking closer at the message, you can see the image download link under the ou key (not sure what that stands for). And that’s really it - each rg_meta tag contains some JSON metadata that provides the useful download link.
I’m still not quite sure why .rg_di nodes are selected though.